Discovering Groups of People in Images
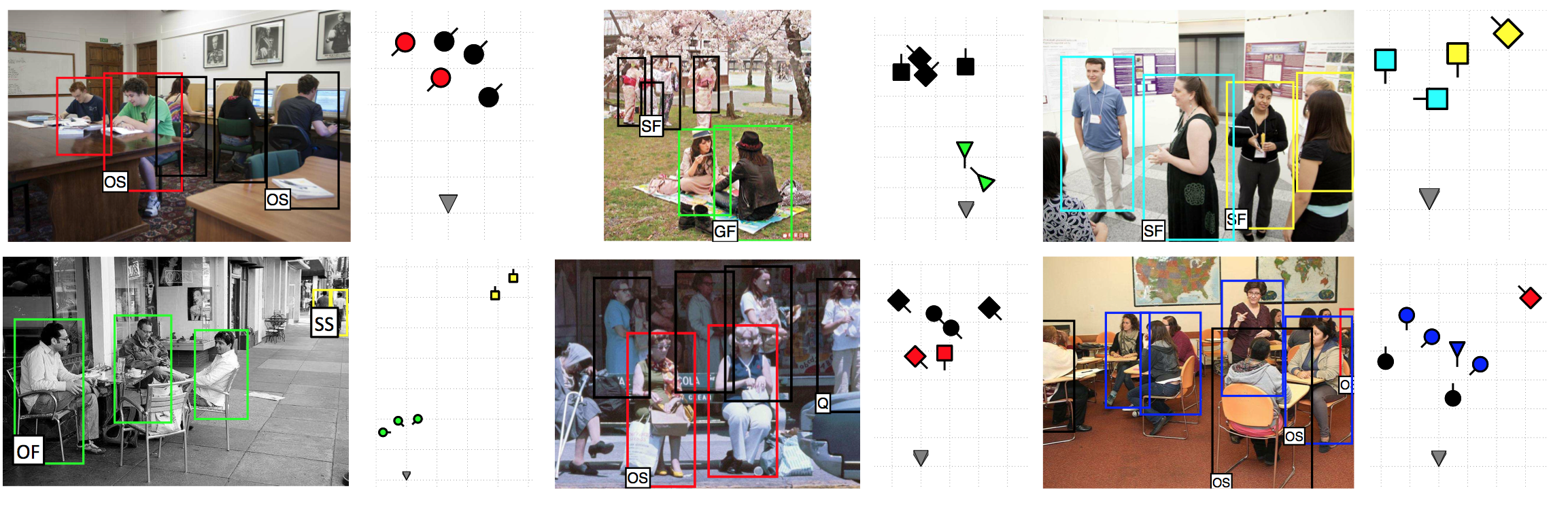
Understanding group activities from images is an important yet challenging task. This is because there is an exponentially large number of semantic and geometrical relationships among individuals that one must model in order to effectively recognize and localize the group activities. Rather than focusing on directly recognizing group activities as most of the previous works do, we advocate the importance of introducing an intermediate representation for modeling groups of humans which we call structure groups. Such groups define the way people spatially interact with each other. People might be facing each other to talk, while others sit on a bench side by side, and some might stand alone. In this paper, we contribute a method for identifying and localizing these structured groups in a single image despite their varying viewpoints, number of participants, and occlusions. We propose to learn an ensemble of discriminative interaction patterns to encode the relationships between people in 3D and introduce a novel efficient iterative augmentation algorithm for solving this complex inference problem. A nice byproduct of the inference scheme is an approximate 3D layout estimate of the structured groups in the scene. Finally, we contribute an extremely challenging new dataset that contains images each showing multiple people performing multiple activities. Extensive evaluation confirms our theoretical findings.
W. Choi, Y. -W. Chao, C. Pantofaru, S. Savarese. "Discovering Groups of People in Images." in ECCV, 2014.
[pdf][supplemetal material][bibtex]
Updates
Source Code
The source code will be available soon.Dataset Downloads
The group discovery dataset is available to download here.The data is released under Creative Common license.
Last updated on 08/31/2014