 |
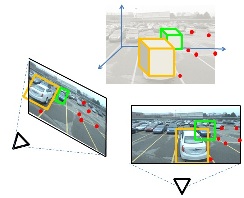
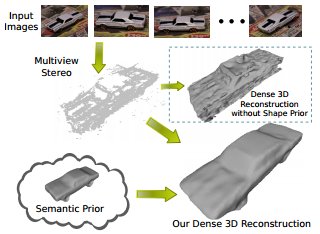
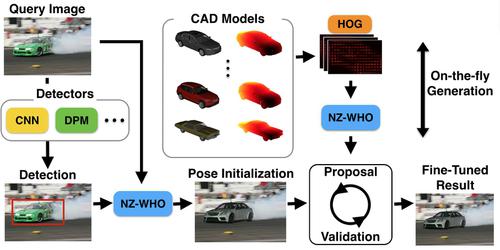
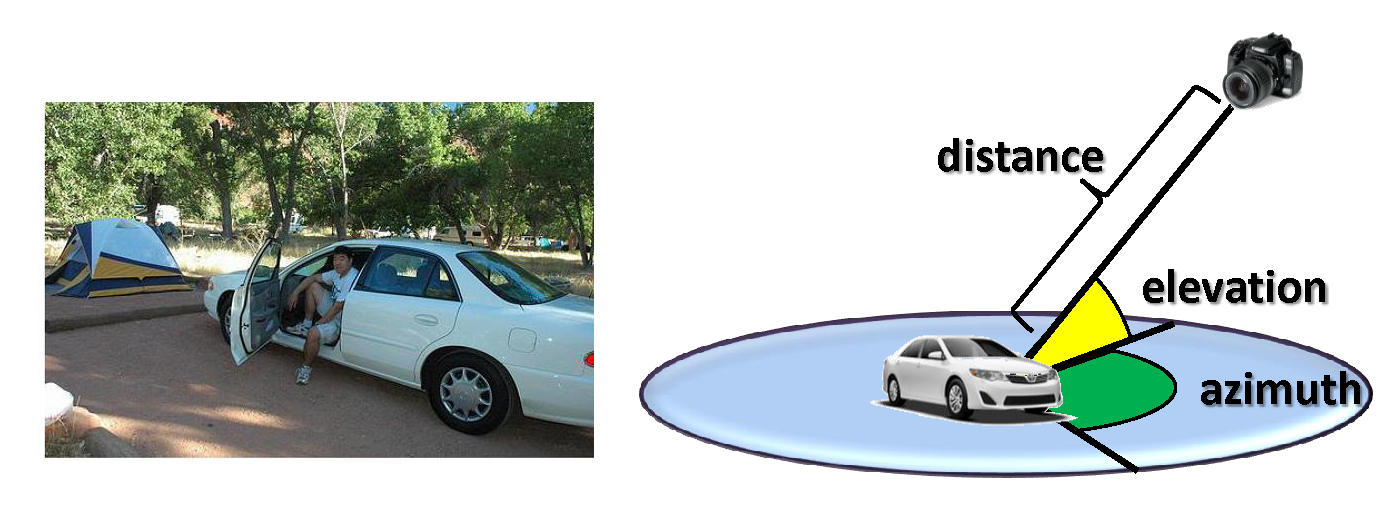
Enriching Object Detection with 2D-3D Registration and Continuous Viewpoint Estimation We propose an efficient method for synthesizing templates from 3D models that runs on the fly -- that is, it quickly produces detectors for an arbitrary viewpoint of a 3D model without expensive dataset-dependent training or template storage. Given a 3D model and an arbitrary continuous detection viewpoint, our method synthesizes a discriminative template by extracting features from a rendered view of the object and decorrelating spatial dependences among the features. Our decorrelation procedure relies on a gradient-based algorithm that is more numerically stable than standard decomposition-based procedures, and we efficiently search for candidate detections by computing FFT-based template convolutions. Due to the speed of our template synthesis procedure, we are able to perform joint optimization of scale, translation, continuous rotation, and focal length using Metropolis-Hastings algorithm. We provide an efficient GPU implementation of our algorithm, and we validate its performance on 3D Object Classes and PASCAL3D+ datasets.
Check out our CVPR 2015 paper and the code
|
 |
A Coarse-to-Fine Model for 3D Pose Estimation and Sub-category Recognition
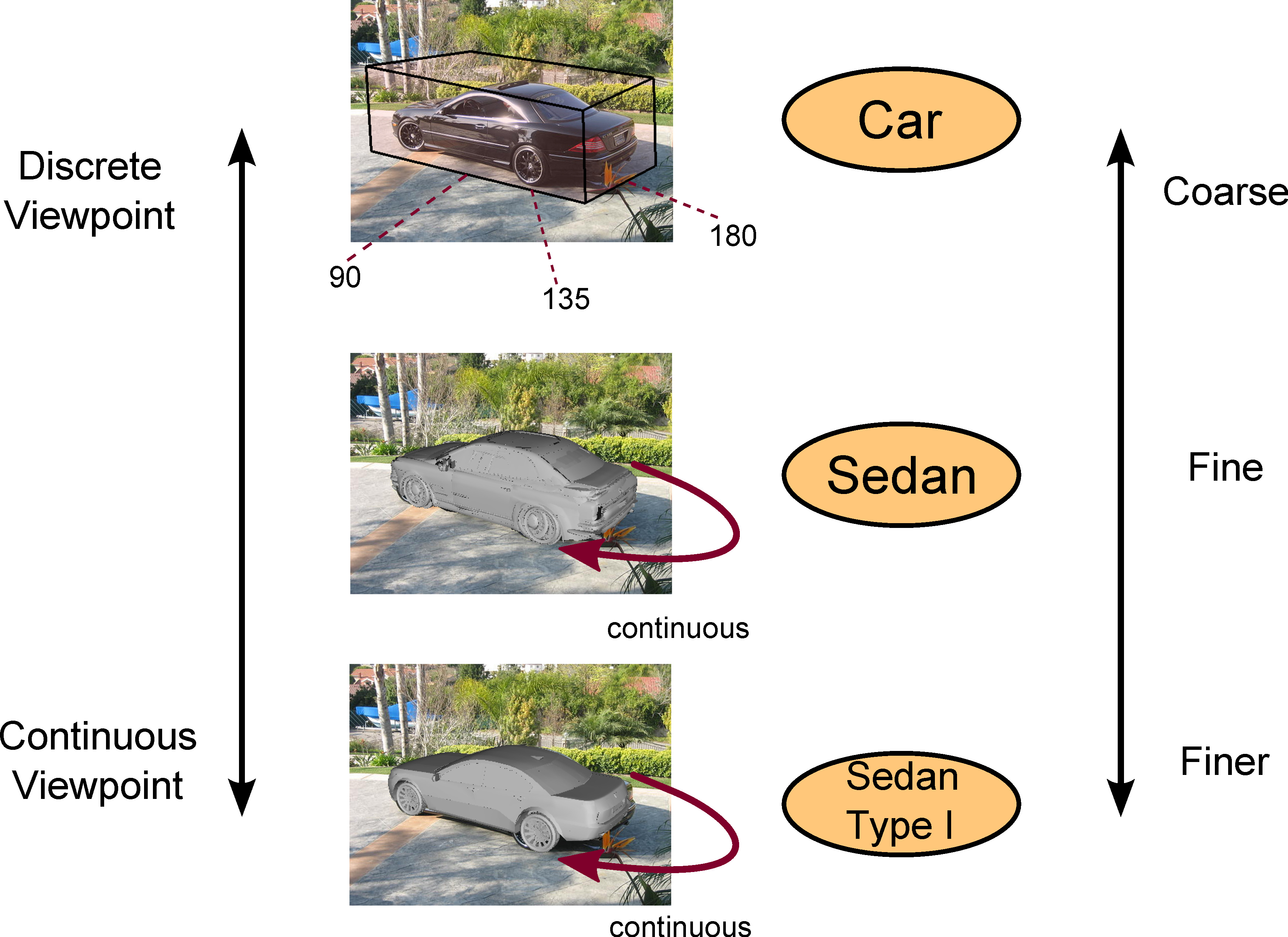
Despite the fact that object detection, 3D pose estimation, and sub-category recognition are highly correlated tasks, they are usually addressed independently from each other because of the huge space of parameters. To jointly model all of these tasks, we propose a coarse-to-fine hierarchical representation, where each level of the hierarchy represents objects at a different level of granularity. The hierarchical representation prevents performance loss, which is often caused by the increase in the number of parameters (as we consider more tasks to model), and the joint modeling enables resolving ambiguities that exist in independent modeling of these tasks.
Check out our CVPR 2015 paper and the project page. The project is sponsored by ONR grant N00014-13-1-0761 and NSF CAREER 1054127. This project is sponsored by NSF CAREER grant (N1054127), Ford-Stanford Innovation Alliance Award, DARPA.
|
 |
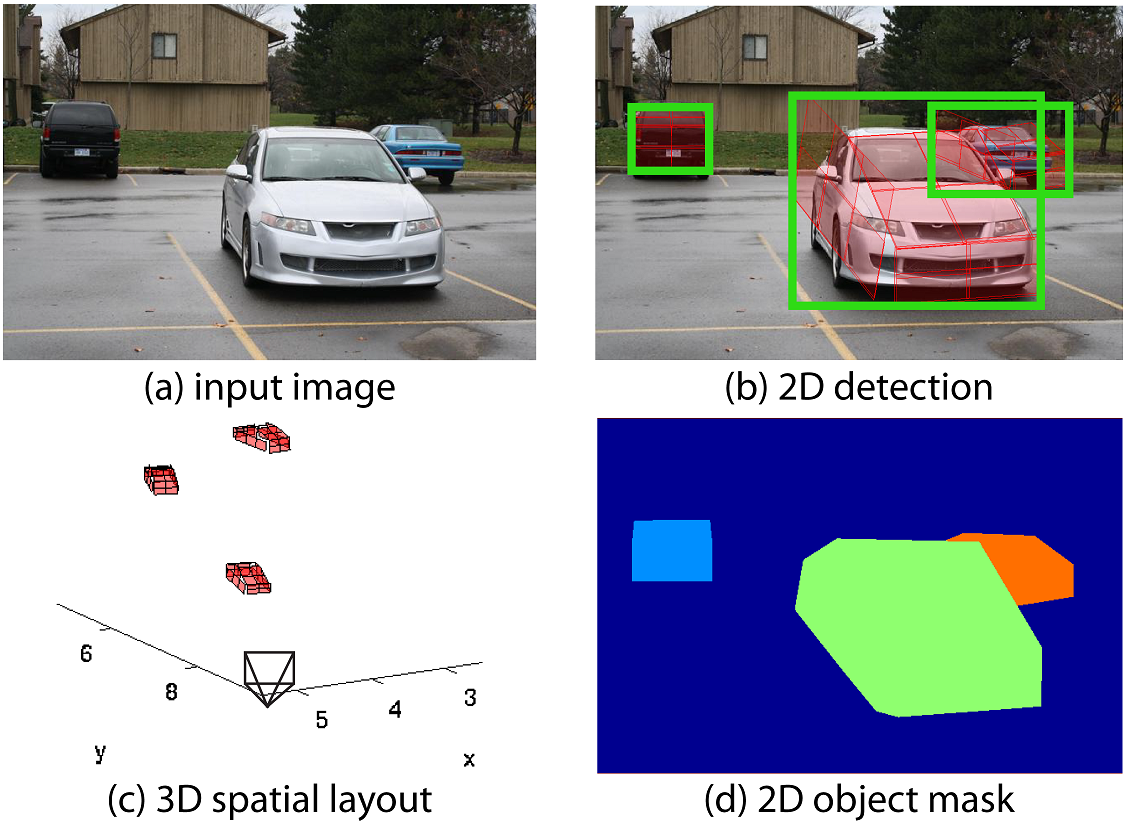
Data-Driven 3D Voxel Patterns for Object Category Recognition
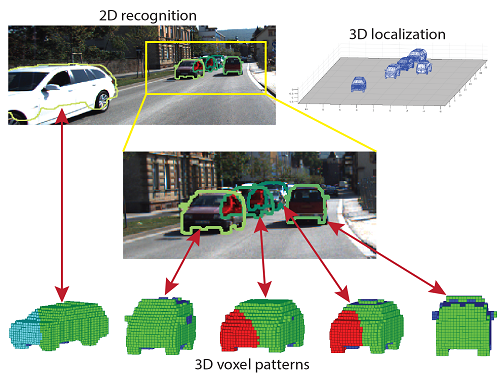
In this wrok, we propose a novel object representation, 3D Voxel Pattern (3DVP), that jointly encodes the key properties of objects including appearance, 3D shape, viewpoint, occlusion and truncation. We discover 3DVPs in a data-driven way, and train a bank of specialized detectors for a dictionary of 3DVPs. The 3DVP detectors are capable of detecting objects with specific visibility patterns and transferring the meta-data from the 3DVPs to the detected objects, such as 2D segmentation mask, 3D pose as well as occlusion or truncation boundaries. The transferred meta-data allows us to infer the occlusion relationship among objects, which in turn provides improved object recognition results.
Check out our CVPR 2015 paper and the project page. The project is sponsored by NSF CAREER grant N.1054127, ONR award N000141110389, and DARPA UPSIDE grant A13-0895-S002.
|
 |
Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild
In this project, we contribute PASCAL3D+ dataset, which is a novel and challenging dataset for 3D object detection and pose estimation. PASCAL3D+ augments 12 rigid categories of the PASCAL VOC 2012 with 3D annotations. Furthermore, more images are added for each category from ImageNet. PASCAL3D+ images exhibit much more variability compared to the existing 3D datasets, and on average there are more than 3,000 object instances per category. We believe this dataset will provide a rich testbed to study 3D detection and pose estimation and will help to significantly push forward research in this area.
Check out our WACV 2014 paper and the project page. The project is sponsored by ONR grant N00014-13-1-0761 and NSF CAREER grant #1054127.
|
 |
Object Detection by 3D Aspectlets and Occlusion Reasoning
In this project, we propose a novel framework for detecting multiple objects from a single image and reasoning about occlusions between objects. We address this problem from a 3D perspective in order to handle various occlusion patterns which can take place between objects. We introduce the concept of “3D aspectlets†based on a piecewise planar object representation. A 3D aspectlet represents a portion of the object which provides evidence for partial observation of the object. A new probabilistic model (which we called spatial layout model) is proposed to combine the bottom-up evidence from 3D aspectlets and the top-down occlusion reasoning to help object detection.
Check out our 3DRR 2013 paper and the project page. The project is sponsored by NSF CAREER grant #1054127, NSF CPS grant #0931474 and a HTC award.
|
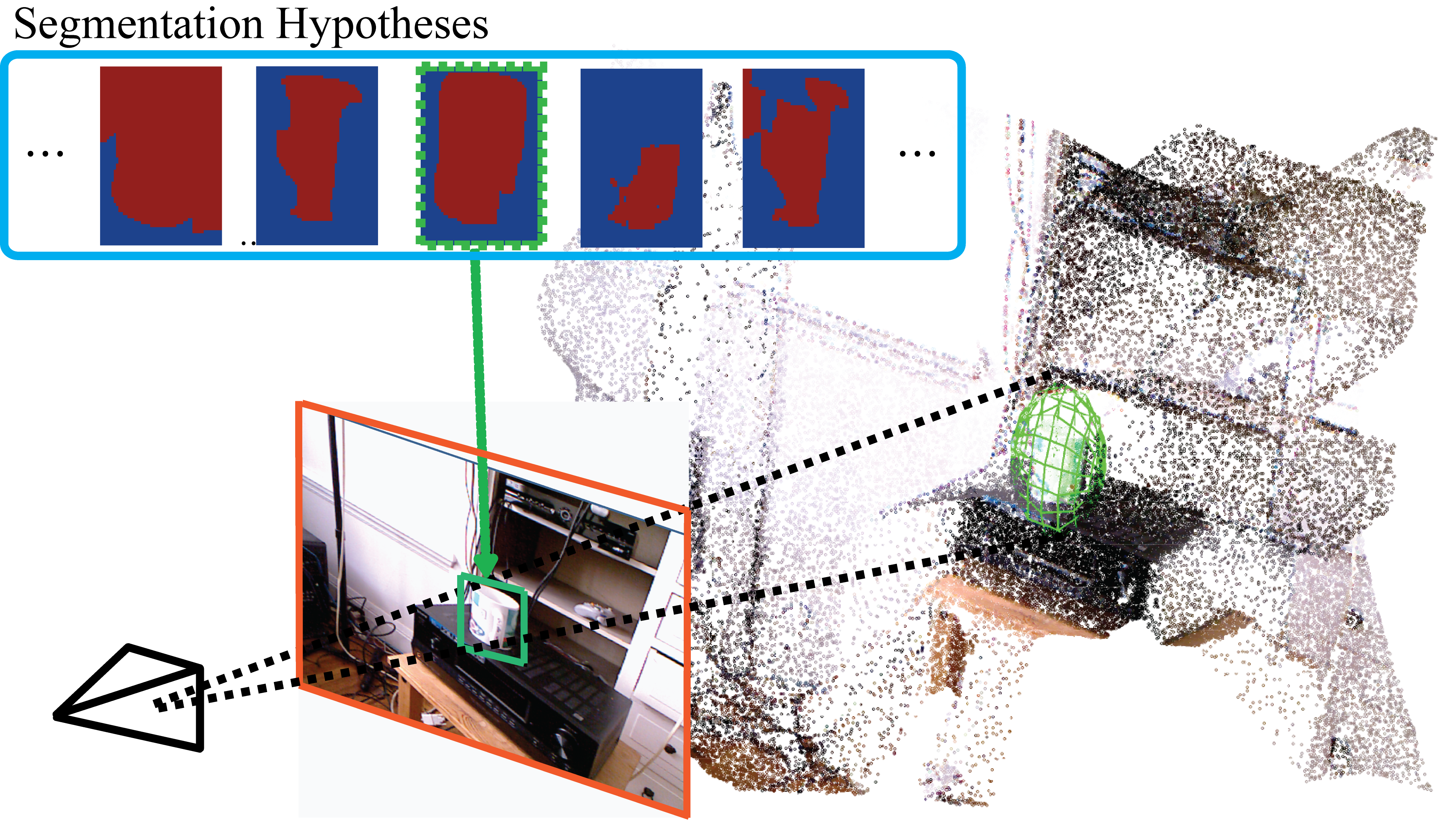 |
Accurate Localization of 3D Objects from RGB-D Data using Segmentation Hypotheses
In this project we focus on the problem of detecting objects in 3D from RGB-D images. We propose a novel framework that explores the compatibility between segmentation hypotheses of the object in the image and the corresponding 3D map. Our framework allows to discover the optimal location of the object using a generalization of the structural latent SVM formulation in 3D. Extensive quantitative and qualitative experimental show that our proposed approach outperforms state-of-the-art as methods for both 3D and 2D object recognition tasks.
Check out our CVPR 2013 paper and the project page. This research is in collaboration with Byung-soo Kim and Shili Xu, and is sponsored by the ARO grant W911NF-09-1-0310, NSF CPS grant #0931474 and a KLA-Tencor Fellowship.
|
 |
Weakly Supervised Learning of Mid-Level Features with Beta-Bernoulli Process Restricted Boltzmann Machines
In this project we develop a new approach to learn mid-level features which capture recognizable semantic concepts. This is achieved by using a weakly supervised approach based on restricted Boltzmann machine (RBM) to learn mid-level features, where only class-level supervision is provided during training. Our experimental results on object recognition tasks show significant performance gains, outperforming existing methods which rely on manually labeled semantic attributes.
Check out our CVPR 2013 paper and the project page. This research is in collaboration with Prof Honglak Lee and Benjamin Kuipers and is sponsored by NSF CPS grant #0931474.
|
 |
Understanding Indoor Scenes using 3D Geometric Phrases
In this project we present a hierarchical scene model for learning and reasoning about complex indoor scenes that can be learned from a reasonable amount of training data, and avoids oversimplification. At the core of this approach is the 3D Geometric Phrase model which captures the semantic and geometric relationships between objects which frequently co-occur in the same 3D spatial configuration. Experiments show that this model effectively explains scene semantics, geometry and object groupings from a single image, while also improving individual object detections.
Check out our CVPR 2013 paper (selected as an oral presentation) and the project page. This work is supported by ONR grant N00014111038 and a gift award from HTC.
|
 |
Object Co-detection
Given a set of images containing the same objects, the goal of co-detection is to detect the objects simultaneously in multiple images, as well as match individual instances across images. Our method can effectively measure object self-occlusions and viewpoint transformations. The co-detector is able to obtain more accurate detection results than if objects were to be detected from each image individually.
Check out our ECCV 2012 paper and the project page. This research is in collaboration with Yingze Bao and Yu Xiang. It is sponsored by NSF CAREER #1054127 and NSF CPS grant #0931474.
|
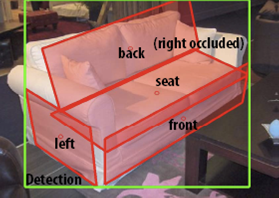 |
Estimating the Aspect Layout of Object Categories
In this project we seek to move away from the traditional paradigm for 2D object recognition whereby objects are identified in the image as 2D bounding boxes. We focus instead on: i) detecting objects; ii) identifying their 3D poses; iii) characterizing the geometrical and topological properties of the objects in terms of their aspect configurations in 3D.
Check out our CVPR 2012 paper and poster. The source code can be downloaded from here. This research is in collaboration with Yu Xiang and is sponsored by ARO W911NF-09-1-0310, NSF CPS grant #0931474 and a KLA-Tencor Fellowship.
|
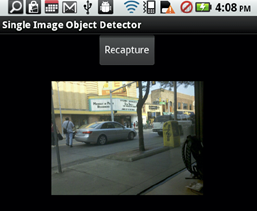 |
Mobile Object Detection through Client-Server based Vote Transfer
In this work we present a novel multi-frame object detection application for the mobile platform that is capable of object localization. We implement the multi-frame detector on a mobile device running the android OS through a novel client-server framework that presents a sound and viable environment for the multi-frame detector.
Check out our CVPR 2012 paper and poster. This research is in collaboration with Shyam Kumar and Min Sun and is sponsored by a Google Research Award and the Gigascale Systems Research Center.
|
 |
Joint Detection and Pose Estimation of Articulated Objects
In this project, we propose an new model called Articulated Part-based Model (APM) for jointly detecting objects (e.g humans) and estimating their poses (e.g. configuration of body parts such as arms, torso, head). APM recursively represents an object as a collection of parts at multiple levels of detail, from coarse-to-fine, where parts at every level are connected to a coarser level through a parent-child relationship. Extensive quantitative and qualitative experimental results on public datasets show that APM outperforms state-of-the-art methods.
In collaboration with Min Sun. Click here for our project webpage and the dataset. Check out our ICCV 2011 paper and poster. This research is sponsored by ARO.
|
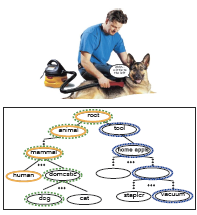 |
Hierarchical Classification of Images by Sparse Approximation
In this project we show that the hierarchical structure of a database can be used successfully to enhance classification accuracy using a sparse approximation framework. We propose a new formulation for sparse approximation where the goal is to discover the sparsest path within the hierarchical data structure that best represents the query object. Extensive quantitative and qualitative experimental evaluation on a number of subsets of the ImageNet database demonstrates our theoretical claims and shows that our approach produces better hierarchical categorization results than competing techniques.
Check out our BMVC 2011 paper and poster. In collaboration with Bying-Soo Kim, Jae Young Park, prof Anna Gilbert; Sponsored by a Google Research Award and the Gigascale Systems Research Center.
|
 |
Depth-Encoded Hough Voting for Joint Object Detection and Shape Recovery
In this project we aim at simultaneously detecting objects, estimating their pose and recovering their 3D shape. We propose a new method called DEHV - Depth-Encoded Hough Voting. DEHV is a probabilistic Hough voting scheme which incorporates depth information into the process of learning distributions of image features (patches) representing an object category. Extensive quantitative and qualitative experimental analysis on existing and newly proposed datasets demonstrates that our approach achieves convincing recognition results and is capable of estimating object shape from just a single image!
Check out our ECCV 2010 paper and poster, and our DIM-PVT 2011 oral paper. Our Dataset (Released Sep,13,2010) is now available.
In collaboration with Min Sun, Gary Bradski, and Bing-Xin Xu. This research is sponsored by the Giga Scale Research Center and NSF grant #0931474.
|
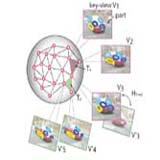 |
Learning a dense multi-view representation for detection, viewpoint classification and synthesis of object categories
We propose a new 3D object class model that is capable of recognizing unseen views by pose estimation and synthesis. We achieve this by using a dense, multiview representation of the viewing sphere parameterized by a triangular mesh of viewpoints. Each triangle of viewpoints can be morphed to synthesize new viewpoints. By incorporating 3D geometrical constraints, our model establishes explicit correspondences among object parts across viewpoints. Click here for our ICCV 09 oral; or here for the CVPR 09 version.
Details on our early work on multi-view object representation can be found in our ICCV 07 paper, or our ECCV 08 paper. Click here for our dataset on multi-view object categories. In collaboration with Min Sun, Hao Su, and Fei-Fei Li.
|
 |
Recognizing the 3D Pose of Object Categories by Manifold Modeling
We propose a novel statistical manifold modeling approach that is capable of classifying poses of object categories from video sequences by simultaneously minimizing the intra-class variability and maximizing inter-pose distance. We model an object category as a collection of non-parametric probability density functions (PDFs) capturing appearance and geometrical changes. We show that the problem of simultaneous intra-class variability minimization and inter-pose distance maximization is equivalent to the one of aligning and expanding the manifolds generated by these non-parametric PDFs, respectively.
Click here for our ICCV 2011 work and here for an earlier version (BMVC 09). In collaboration with Liang Mei, Jingen Liu and Alfred Hero; Sponsored by ARO Army and NSF grant #0931474.
|
 |
Capturing spatial-temporal relationships for object and action categorization
In this work we present a novel framework for learning the typical spatial-temporal relationship between object parts. These relationships are incorporated in a flexible model for object and action categorization.
Click here for the original CVPR 06 paper or here for the WMVC08 work on action categorization. In collaboration with Andrey Del Pozo, Juan Carlos Niebles, Li Fei-Fei, John Winn and Antonio Criminisi.
|
| top |